正则 正则表达式教程 正则表达式 教程 固化分组 占有优先量词 技术 正则表达式教程六 —— 回溯、固化分组和占有优先量词 2018-01-11 16:27 4100 更新于 2018-01-11 16:27 ## 什么是回溯呢? 正则在处理各个子表达式的时候,当遇到需要在两个或多个成功的可能中进行选择的时候,它会选择其中一个; 并记住开始选择的位置和未尝试的分支在字符串中位置(备用状态) 若第一个选择匹配正确时,即匹配完成,若匹配失败,它将返回(回溯)刚才做出选择的位置,选择其它备选分支进行匹配。 不是很好理解,来个例子 ### 例子29 ```php $s = <<<'TEXT' in my mind make mistake TEXT; preg_match_all('#mi(ss|nd)#',$s,$m); echo "<pre>"; print_r($m); echo "</pre>"; /* Array ( [0] => Array ( [0] => mind ) [1] => Array ( [0] => nd ) ) */ ``` 当正则匹配到 `in my mind` 中的 i 时发现有多条路可选,好,记下位置,选择第一个可能,匹配是否有`s`,没有,这条分支错误 返回到选择处,开始第二种可能,匹配成功,整个表达式匹配失败 在匹配 `make mistake` 的时候,发现两个分支都匹配失败,整个表达式匹配失败 再来看看回溯的另一个例子,使用量词(限定符)的例子 ### 例子30 ```php $s = <<<'TEXT' abc123456def TEXT; preg_match_all('#.*(\d\d)#',$s,$m); echo "<pre>"; print_r($m); echo "</pre>"; /* Array ( [0] => Array ( [0] => abc123456 ) [1] => Array ( [0] => 56 ) ) */ ``` 由于我一开始就使用 `.*` ,而 `*` 是尽可能多的匹配,所以 `.*` 匹配了完整的字符串 `abc123456def`,并且保存了它们的位置(备用状态) 因为 `.` 是匹配任意字符,所以字符串中的每个字母或数字都保存了位置(备用状态) 那么在执行到表达式 `(\d\d)` 时,发现后面没有字符可以匹配了,那怎么办? 因为 `*` 是匹配零次或多次,那么就把匹配的内容给我吐出来(交还),回溯到之前最近的一个位置,现在这个位置就是 `f` 但是发现还是不匹配,因为我要数字,那么就再交还一个,回溯到位置 `e` 就这样`回溯-尝试匹配`,直到回溯到 6 的位置,交给第一个 `\d` 匹配,发现成功了,接着执行第二个 `\d` 的时候,发现是 d,匹配失败,再回溯 直到回溯到 5 位置时,5和6刚好满足 `\d\d`,完成匹配,匹配成功 ## 回溯的两个知识点 ### 1、什么时候开始回溯? 当然是匹配失败。 ### 2、回溯到什么位置? 回溯到表达式开始执行分支表达式时的位置。若有多个多选位置时,回溯到底回到哪个位置呢?当然是回溯到最近存储位置的地方,原则就是后进先出 接下来,我们先看一个需求 ### 例子31 ```php $s = <<<'TEXT' 0.620 0.625 0.62507 TEXT; preg_match_all('#(\.\d\d[1-9]?)\d+#s',$s,$m); echo "<pre>"; print_r($m); echo "</pre>"; /* Array ( [0] => Array ( [0] => .620 [1] => .625 [2] => .62500 ) [1] => Array ( [0] => .62 [1] => .62 [2] => .625 ) ) */ ``` 将数字保留2-3位小数,并且最后一位不能为0(为做演示,在这个例子中我是匹配出来) 为什么有 `[1-9]?` 这个表达式呢,这是为了匹配不等0的第三位数字 这个表达式匹配到了 `.625` ,这肯定是不好的,因为 .625 替换为 .62 为什么呢?因为 `[1-9]?` 使用了量词 `?` ,匹配了 5,并保存了备用状态,而后面的 `\d+` 匹配不到内容,正则进行了回溯(如例子30) 将 5 交还给了 `\d+` ,匹配成功,所以匹配到的内容就是 .62 ------------ 那么有没有一种方法让 `[1-9]?` 匹配到的内容不交还呢?也就是说,如果 `[1-9]?` 匹配成功,就不保存备用状态,那么它就不会交还 这就要用到`固化分组`和`占有优先量词` ## 固化分组 (?>pattern) pattern 为正常的子表达式,`(?>...)` 中匹配的内容将作为一个整体被保留(匹配成功,锁定状态,不能被回溯)或丢弃(匹配失败) 以上面的例子为例,正则表达式改写为 `#(\.\d\d(?>[1-9]?))\d+#` ,匹配 0.625 时,`[1-9]?` 匹配到了 5 ,而 `\d+` 必须要匹配一个数字 但是后面没有数字让它匹配,那么就要进行回溯,但是发现没有备用状态可供使用,匹配失败,那么 0.625 将不会进行替换,这是正确的 ## 正确使用固化分组,可以提高正则表达式的匹配速度! 为什么这么说呢?上面说了,使用固化分组可以不保存备用状态,就不会回溯进行多次匹配尝试,举一个例子 我使用 `\w+:` 匹配字符串 test1 ,首先 `\w+` 就匹配到了 test1 ,因为使用了量词 `+` ,所以创建了多个备用状态,由于 `:`** 没有匹配到** 所以进行回溯,交还 1 用来匹配` :`,匹配失败,再交还 `t` 用来匹配 `:` ,直到匹配 `e` 失败的时候,发现没有备用状态可用 (因为 `+` 号至少匹配一次,所以第一个t不会被交还),整个匹配失败。 这走了多少冤枉路啊,因为我们的目的很明确,就是匹配数字或字母后面是冒号的字符串,但却进行了多次回溯,大大降低了匹配速度 匹配的原理图如下 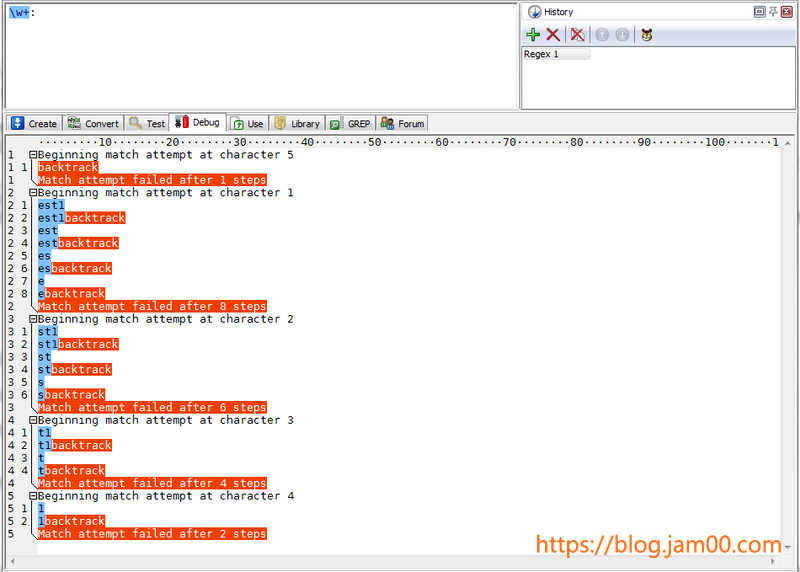 若改为固化分组的写法 `(?>\w+):` ,test1 被匹配了,`:` 没有被匹配,且没有备用状态可供使用,匹配失败。是不是很快?! 那么例子31 的正则,就可以改写成 `#(\.\d\d(?>[1-9]?))\d+#`,匹配结果就为 ``` Array ( [0] => Array ( [0] => .620 [1] => .6257 ) [1] => Array ( [0] => .62 [1] => .625 ) ) ``` 这里为什么 0.620 被匹配了?因为 `[1-9]?` 不匹配 0,所以 0 被 \d+ 匹配了,所以匹配成功 ## 占有优先量词 ?+ , *? , ++ ,{m,n}+ 和固化分组一样, 占有优先量词也不交还已经匹配的字符。写法就是在量词(限定符)后面跟一个 `+` 号 那么例子31的占有优先量词的写法就是:`#(\.\d\d[1-9]?+)\d+#`,结果和固化分组一样 这节大家就要多理解固化分组对于匹配效率的重要性。